Chapter 15 – Processing Sequences Using RNNs and CNNs
This notebook contains all the sample code in chapter 15.
|
|
Setup
First, let’s import a few common modules, ensure MatplotLib plots figures inline and prepare a function to save the figures. We also check that Python 3.5 or later is installed (although Python 2.x may work, it is deprecated so we strongly recommend you use Python 3 instead), as well as Scikit-Learn ≥0.20 and TensorFlow ≥2.0.
# Python ≥3.5 is required
import sys
assert sys.version_info >= (3, 5)
# Scikit-Learn ≥0.20 is required
import sklearn
assert sklearn.__version__ >= "0.20"
try:
# %tensorflow_version only exists in Colab.
%tensorflow_version 2.x
IS_COLAB = True
except Exception:
IS_COLAB = False
# TensorFlow ≥2.0 is required
import tensorflow as tf
from tensorflow import keras
assert tf.__version__ >= "2.0"
if not tf.test.is_gpu_available():
print("No GPU was detected. LSTMs and CNNs can be very slow without a GPU.")
if IS_COLAB:
print("Go to Runtime > Change runtime and select a GPU hardware accelerator.")
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
tf.random.set_seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "rnn"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
Basic RNNs
Generate the Dataset
def generate_time_series(batch_size, n_steps):
freq1, freq2, offsets1, offsets2 = np.random.rand(4, batch_size, 1)
time = np.linspace(0, 1, n_steps)
series = 0.5 * np.sin((time - offsets1) * (freq1 * 10 + 10)) # wave 1
series += 0.2 * np.sin((time - offsets2) * (freq2 * 20 + 20)) # + wave 2
series += 0.1 * (np.random.rand(batch_size, n_steps) - 0.5) # + noise
return series[..., np.newaxis].astype(np.float32)
np.random.seed(42)
n_steps = 50
series = generate_time_series(10000, n_steps + 1)
X_train, y_train = series[:7000, :n_steps], series[:7000, -1]
X_valid, y_valid = series[7000:9000, :n_steps], series[7000:9000, -1]
X_test, y_test = series[9000:, :n_steps], series[9000:, -1]
X_train.shape, y_train.shape
def plot_series(series, y=None, y_pred=None, x_label="$t$", y_label="$x(t)$"):
plt.plot(series, ".-")
if y is not None:
plt.plot(n_steps, y, "bx", markersize=10)
if y_pred is not None:
plt.plot(n_steps, y_pred, "ro")
plt.grid(True)
if x_label:
plt.xlabel(x_label, fontsize=16)
if y_label:
plt.ylabel(y_label, fontsize=16, rotation=0)
plt.hlines(0, 0, 100, linewidth=1)
plt.axis([0, n_steps + 1, -1, 1])
fig, axes = plt.subplots(nrows=1, ncols=3, sharey=True, figsize=(12, 4))
for col in range(3):
plt.sca(axes[col])
plot_series(X_valid[col, :, 0], y_valid[col, 0],
y_label=("$x(t)$" if col==0 else None))
save_fig("time_series_plot")
plt.show()
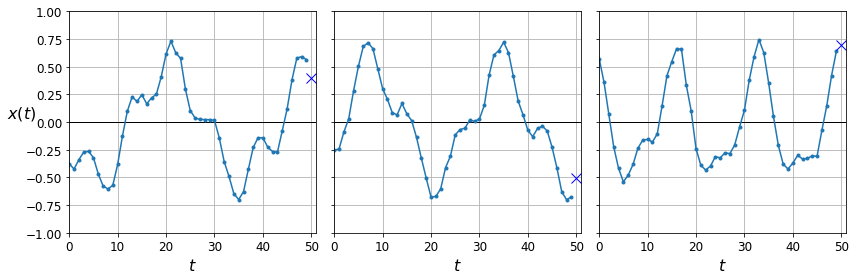
Computing Some Baselines
Naive predictions (just predict the last observed value):
y_pred = X_valid[:, -1]
np.mean(keras.losses.mean_squared_error(y_valid, y_pred))
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()
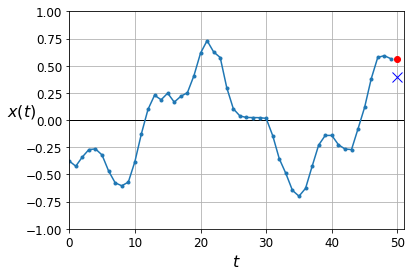
Linear predictions:
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[50, 1]),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer="adam")
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid)
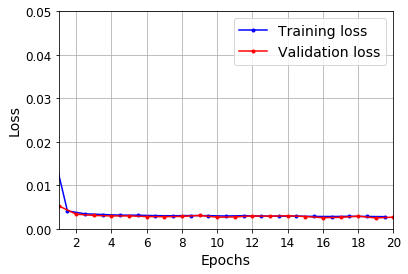
def plot_learning_curves(loss, val_loss):
plt.plot(np.arange(len(loss)) + 0.5, loss, "b.-", label="Training loss")
plt.plot(np.arange(len(val_loss)) + 1, val_loss, "r.-", label="Validation loss")
plt.gca().xaxis.set_major_locator(mpl.ticker.MaxNLocator(integer=True))
plt.axis([1, 20, 0, 0.05])
plt.legend(fontsize=14)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.grid(True)
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show()
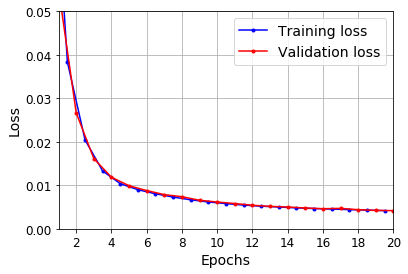
y_pred = model.predict(X_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()
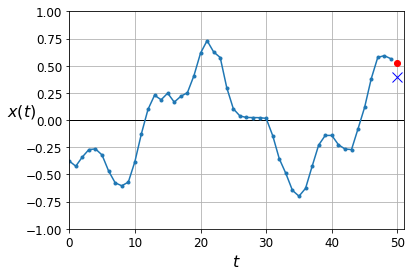
Using a Simple RNN
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(1, input_shape=[None, 1])
])
optimizer = keras.optimizers.Adam(lr=0.005)
model.compile(loss="mse", optimizer=optimizer)
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid)
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show()
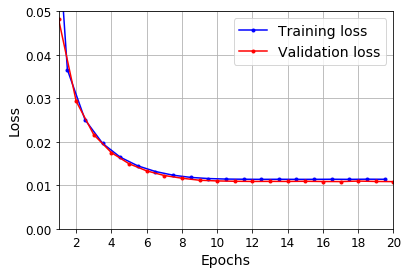
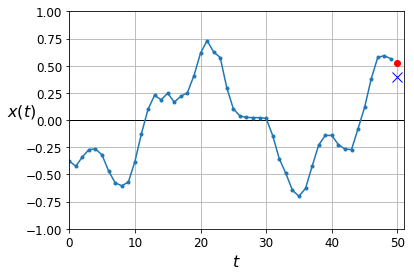
y_pred = model.predict(X_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()
Deep RNNs
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20, return_sequences=True),
keras.layers.SimpleRNN(1)
])
model.compile(loss="mse", optimizer="adam")
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid)
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show()
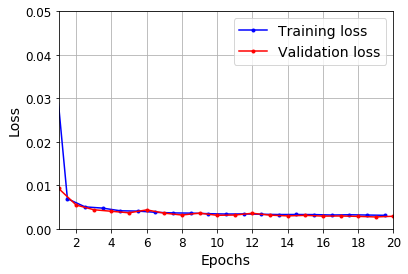
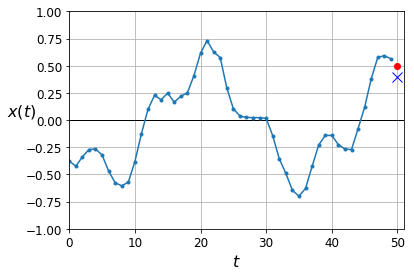
y_pred = model.predict(X_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()
Make the second SimpleRNN layer return only the last output:
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer="adam")
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
model.evaluate(X_valid, y_valid)
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show()
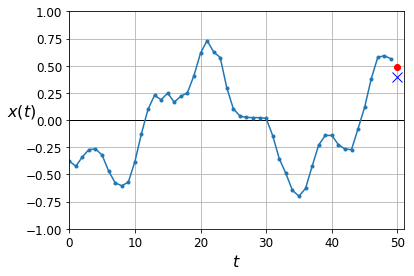
y_pred = model.predict(X_valid)
plot_series(X_valid[0, :, 0], y_valid[0, 0], y_pred[0, 0])
plt.show()
Forecasting Several Steps Ahead
np.random.seed(43) # not 42, as it would give the first series in the train set
series = generate_time_series(1, n_steps + 10)
X_new, Y_new = series[:, :n_steps], series[:, n_steps:]
X = X_new
for step_ahead in range(10):
y_pred_one = model.predict(X[:, step_ahead:])[:, np.newaxis, :]
X = np.concatenate([X, y_pred_one], axis=1)
Y_pred = X[:, n_steps:]
Y_pred.shape
def plot_multiple_forecasts(X, Y, Y_pred):
n_steps = X.shape[1]
ahead = Y.shape[1]
plot_series(X[0, :, 0])
plt.plot(np.arange(n_steps, n_steps + ahead), Y[0, :, 0], "ro-", label="Actual")
plt.plot(np.arange(n_steps, n_steps + ahead), Y_pred[0, :, 0], "bx-", label="Forecast", markersize=10)
plt.axis([0, n_steps + ahead, -1, 1])
plt.legend(fontsize=14)
plot_multiple_forecasts(X_new, Y_new, Y_pred)
save_fig("forecast_ahead_plot")
plt.show()
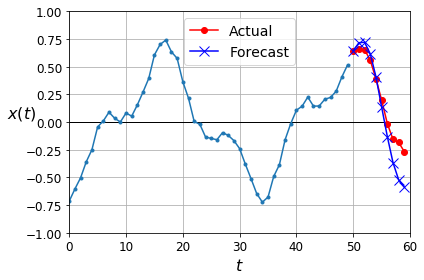
Now let’s use this model to predict the next 10 values. We first need to regenerate the sequences with 9 more time steps.
np.random.seed(42)
n_steps = 50
series = generate_time_series(10000, n_steps + 10)
X_train, Y_train = series[:7000, :n_steps], series[:7000, -10:, 0]
X_valid, Y_valid = series[7000:9000, :n_steps], series[7000:9000, -10:, 0]
X_test, Y_test = series[9000:, :n_steps], series[9000:, -10:, 0]
Now let’s predict the next 10 values one by one:
X = X_valid
for step_ahead in range(10):
y_pred_one = model.predict(X)[:, np.newaxis, :]
X = np.concatenate([X, y_pred_one], axis=1)
Y_pred = X[:, n_steps:, 0]
Y_pred.shape
np.mean(keras.metrics.mean_squared_error(Y_valid, Y_pred))
Let’s compare this performance with some baselines: naive predictions and a simple linear model:
Y_naive_pred = Y_valid[:, -1:]
np.mean(keras.metrics.mean_squared_error(Y_valid, Y_naive_pred))
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[50, 1]),
keras.layers.Dense(10)
])
model.compile(loss="mse", optimizer="adam")
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
Now let’s create an RNN that predicts all 10 next values at once:
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20),
keras.layers.Dense(10)
])
model.compile(loss="mse", optimizer="adam")
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
np.random.seed(43)
series = generate_time_series(1, 50 + 10)
X_new, Y_new = series[:, :50, :], series[:, -10:, :]
Y_pred = model.predict(X_new)[..., np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)
plt.show()
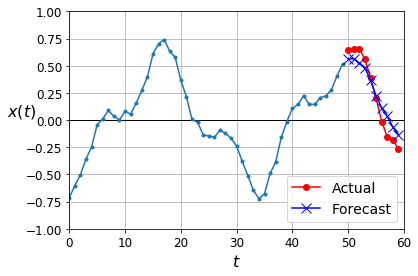
Now let’s create an RNN that predicts the next 10 steps at each time step. That is, instead of just forecasting time steps 50 to 59 based on time steps 0 to 49, it will forecast time steps 1 to 10 at time step 0, then time steps 2 to 11 at time step 1, and so on, and finally it will forecast time steps 50 to 59 at the last time step. Notice that the model is causal: when it makes predictions at any time step, it can only see past time steps.
np.random.seed(42)
n_steps = 50
series = generate_time_series(10000, n_steps + 10)
X_train = series[:7000, :n_steps]
X_valid = series[7000:9000, :n_steps]
X_test = series[9000:, :n_steps]
Y = np.empty((10000, n_steps, 10))
for step_ahead in range(1, 10 + 1):
Y[..., step_ahead - 1] = series[..., step_ahead:step_ahead + n_steps, 0]
Y_train = Y[:7000]
Y_valid = Y[7000:9000]
Y_test = Y[9000:]
X_train.shape, Y_train.shape
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.SimpleRNN(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
def last_time_step_mse(Y_true, Y_pred):
return keras.metrics.mean_squared_error(Y_true[:, -1], Y_pred[:, -1])
model.compile(loss="mse", optimizer=keras.optimizers.Adam(lr=0.01), metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
np.random.seed(43)
series = generate_time_series(1, 50 + 10)
X_new, Y_new = series[:, :50, :], series[:, 50:, :]
Y_pred = model.predict(X_new)[:, -1][..., np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)
plt.show()
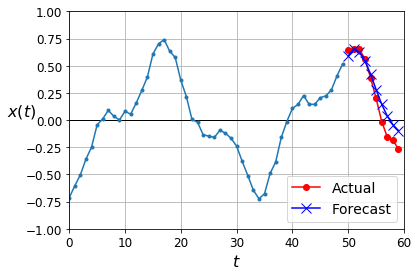
Deep RNN with Batch Norm
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.SimpleRNN(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.BatchNormalization(),
keras.layers.SimpleRNN(20, return_sequences=True),
keras.layers.BatchNormalization(),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
Deep RNNs with Layer Norm
from tensorflow.keras.layers import LayerNormalization
class LNSimpleRNNCell(keras.layers.Layer):
def __init__(self, units, activation="tanh", **kwargs):
super().__init__(**kwargs)
self.state_size = units
self.output_size = units
self.simple_rnn_cell = keras.layers.SimpleRNNCell(units,
activation=None)
self.layer_norm = LayerNormalization()
self.activation = keras.activations.get(activation)
def get_initial_state(self, inputs=None, batch_size=None, dtype=None):
if inputs is not None:
batch_size = tf.shape(inputs)[0]
dtype = inputs.dtype
return [tf.zeros([batch_size, self.state_size], dtype=dtype)]
def call(self, inputs, states):
outputs, new_states = self.simple_rnn_cell(inputs, states)
norm_outputs = self.activation(self.layer_norm(outputs))
return norm_outputs, [norm_outputs]
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True,
input_shape=[None, 1]),
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
Creating a Custom RNN Class
class MyRNN(keras.layers.Layer):
def __init__(self, cell, return_sequences=False, **kwargs):
super().__init__(**kwargs)
self.cell = cell
self.return_sequences = return_sequences
self.get_initial_state = getattr(
self.cell, "get_initial_state", self.fallback_initial_state)
def fallback_initial_state(self, inputs):
return [tf.zeros([self.cell.state_size], dtype=inputs.dtype)]
@tf.function
def call(self, inputs):
states = self.get_initial_state(inputs)
n_steps = tf.shape(inputs)[1]
if self.return_sequences:
sequences = tf.TensorArray(inputs.dtype, size=n_steps)
outputs = tf.zeros(shape=[n_steps, self.cell.output_size], dtype=inputs.dtype)
for step in tf.range(n_steps):
outputs, states = self.cell(inputs[:, step], states)
if self.return_sequences:
sequences = sequences.write(step, outputs)
if self.return_sequences:
return sequences.stack()
else:
return outputs
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
MyRNN(LNSimpleRNNCell(20), return_sequences=True,
input_shape=[None, 1]),
MyRNN(LNSimpleRNNCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
LSTMs
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.LSTM(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.LSTM(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
model.evaluate(X_valid, Y_valid)
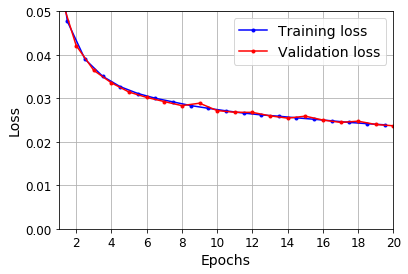
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show()
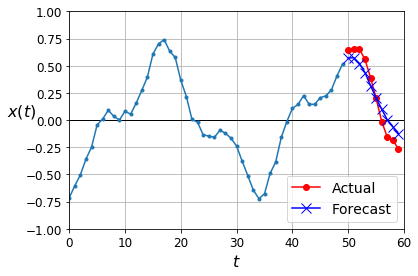
np.random.seed(43)
series = generate_time_series(1, 50 + 10)
X_new, Y_new = series[:, :50, :], series[:, 50:, :]
Y_pred = model.predict(X_new)[:, -1][..., np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)
plt.show()
GRUs
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.GRU(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.GRU(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
model.evaluate(X_valid, Y_valid)
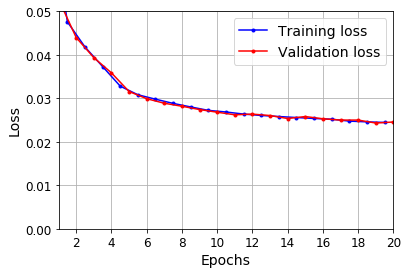
plot_learning_curves(history.history["loss"], history.history["val_loss"])
plt.show()
np.random.seed(43)
series = generate_time_series(1, 50 + 10)
X_new, Y_new = series[:, :50, :], series[:, 50:, :]
Y_pred = model.predict(X_new)[:, -1][..., np.newaxis]
plot_multiple_forecasts(X_new, Y_new, Y_pred)
plt.show()
Using One-Dimensional Convolutional Layers to Process Sequences
1D conv layer with kernel size 4, stride 2, VALID padding:
|-----2-----| |-----5---...------| |-----23----|
|-----1-----| |-----4-----| ... |-----22----|
|-----0----| |-----3-----| |---...|-----21----|
X: 0 1 2 3 4 5 6 7 8 9 10 11 12 ... 42 43 44 45 46 47 48 49
Y: 1 2 3 4 5 6 7 8 9 10 11 12 13 ... 43 44 45 46 47 48 49 50
/10 11 12 13 14 15 16 17 18 19 20 21 22 ... 52 53 54 55 56 57 58 59
Output:
X: 0/3 2/5 4/7 6/9 8/11 10/13 .../43 42/45 44/47 46/49
Y: 4/13 6/15 8/17 10/19 12/21 14/23 .../53 46/55 48/57 50/59
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential([
keras.layers.Conv1D(filters=20, kernel_size=4, strides=2, padding="valid",
input_shape=[None, 1]),
keras.layers.GRU(20, return_sequences=True),
keras.layers.GRU(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train[:, 3::2], epochs=20,
validation_data=(X_valid, Y_valid[:, 3::2]))
WaveNet
C2 /\ /\ /\ /\ /\ /\ /\ /\ /\ /\ /\ /\ /\.../\ /\ /\ /\ /\ /\
\ / \ / \ / \ / \ / \ / \ / \ / \ / \
/ \ / \ / \ / \
C1 /\ /\ /\ /\ /\ /\ /\ /\ /\ /\ /\ /\ /.../\ /\ /\ /\ /\ /\ /\
X: 0 1 2 3 4 5 6 7 8 9 10 11 12 ... 43 44 45 46 47 48 49
Y: 1 2 3 4 5 6 7 8 9 10 11 12 13 ... 44 45 46 47 48 49 50
/10 11 12 13 14 15 16 17 18 19 20 21 22 ... 53 54 55 56 57 58 59
np.random.seed(42)
tf.random.set_seed(42)
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape=[None, 1]))
for rate in (1, 2, 4, 8) * 2:
model.add(keras.layers.Conv1D(filters=20, kernel_size=2, padding="causal",
activation="relu", dilation_rate=rate))
model.add(keras.layers.Conv1D(filters=10, kernel_size=1))
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
Here is the original WaveNet defined in the paper: it uses Gated Activation Units instead of ReLU and parametrized skip connections, plus it pads with zeros on the left to avoid getting shorter and shorter sequences:
class GatedActivationUnit(keras.layers.Layer):
def __init__(self, activation="tanh", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
def call(self, inputs):
n_filters = inputs.shape[-1] // 2
linear_output = self.activation(inputs[..., :n_filters])
gate = keras.activations.sigmoid(inputs[..., n_filters:])
return self.activation(linear_output) * gate
def wavenet_residual_block(inputs, n_filters, dilation_rate):
z = keras.layers.Conv1D(2 * n_filters, kernel_size=2, padding="causal",
dilation_rate=dilation_rate)(inputs)
z = GatedActivationUnit()(z)
z = keras.layers.Conv1D(n_filters, kernel_size=1)(z)
return keras.layers.Add()([z, inputs]), z
keras.backend.clear_session()
np.random.seed(42)
tf.random.set_seed(42)
n_layers_per_block = 3 # 10 in the paper
n_blocks = 1 # 3 in the paper
n_filters = 32 # 128 in the paper
n_outputs = 10 # 256 in the paper
inputs = keras.layers.Input(shape=[None, 1])
z = keras.layers.Conv1D(n_filters, kernel_size=2, padding="causal")(inputs)
skip_to_last = []
for dilation_rate in [2**i for i in range(n_layers_per_block)] * n_blocks:
z, skip = wavenet_residual_block(z, n_filters, dilation_rate)
skip_to_last.append(skip)
z = keras.activations.relu(keras.layers.Add()(skip_to_last))
z = keras.layers.Conv1D(n_filters, kernel_size=1, activation="relu")(z)
Y_proba = keras.layers.Conv1D(n_outputs, kernel_size=1, activation="softmax")(z)
model = keras.models.Model(inputs=[inputs], outputs=[Y_proba])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=2,
validation_data=(X_valid, Y_valid))
In this chapter we explored the fundamentals of RNNs and used them to process sequences (namely, time series). In the process we also looked at other ways to process sequences, including CNNs. In the next chapter we will use RNNs for Natural Language Processing, and we will learn more about RNNs (bidirectional RNNs, stateful vs stateless RNNs, Encoder–Decoders, and Attention-augmented Encoder-Decoders). We will also look at the Transformer, an Attention-only architecture.
Exercise solutions
1. to 6.
See Appendix A.
7. Embedded Reber Grammars
First we need to build a function that generates strings based on a grammar. The grammar will be represented as a list of possible transitions for each state. A transition specifies the string to output (or a grammar to generate it) and the next state.
np.random.seed(42)
default_reber_grammar = [
[("B", 1)], # (state 0) =B=>(state 1)
[("T", 2), ("P", 3)], # (state 1) =T=>(state 2) or =P=>(state 3)
[("S", 2), ("X", 4)], # (state 2) =S=>(state 2) or =X=>(state 4)
[("T", 3), ("V", 5)], # and so on...
[("X", 3), ("S", 6)],
[("P", 4), ("V", 6)],
[("E", None)]] # (state 6) =E=>(terminal state)
embedded_reber_grammar = [
[("B", 1)],
[("T", 2), ("P", 3)],
[(default_reber_grammar, 4)],
[(default_reber_grammar, 5)],
[("T", 6)],
[("P", 6)],
[("E", None)]]
def generate_string(grammar):
state = 0
output = []
while state is not None:
index = np.random.randint(len(grammar[state]))
production, state = grammar[state][index]
if isinstance(production, list):
production = generate_string(grammar=production)
output.append(production)
return "".join(output)
Let’s generate a few strings based on the default Reber grammar:
for _ in range(25):
print(generate_string(default_reber_grammar), end=" ")
Let’s look at a few corrupted strings:
for _ in range(25):
print(generate_corrupted_string(embedded_reber_grammar), end=" ")
To be continued…